昨年から、HTAP (Hybrid Transactional/Analytical Processing) を実現する為の手法に興味を持っています。
HTAP を実現する為に、DB の内部では row-wise / column-wise それぞれの形式でレコードを保持するのが一般的です。それらのレコードを効率的に保存、活用する手法について何か面白い話は無いか調べてみたところ、『Towards a One Size Fits All Database Architecture』 という 2011 年の Paper があったので、読んでみました。
Conclusion 以外は要約です。
Introduction
90年代半ばには、data warehouse のエンジニアは、当時の DB がデータサイズや OLAP の複雑なクエリに対応するのは不十分であることが分かっていた。それ故、分析用に column-wise な DB を作り、分析はその DB を使うようにした。このように、用途によって DB を分けるようになった。ストリームを扱うシステム (data stream management systems: DSMS) もその一つ。その結果、ETL パイプラインを用意する等してデータをコピーし、複数の DB を管理することなる。複数の DB のユースケースをカバーする単一の効果的なシステムを構築したい。それが OctopusDB である。
OctopusDB
The Primary Log Store
- row-, column- といったストレージを持たない
- 代わりに、sequential にログを記録する
- ログは HDD や SDD といった durable storage に保存する
- ログレコードには lsn(log sequence number), 操作(method), parameters を記録する
Storage View
- ログを別の物理レイアウトで表現したものを Storage View(SV) とする
- RowSV: row-wise な SV
- ColSV: column-wise な SV
- IndexSV: インデックス(B+Tree, Hash, Bitmap,…)
- ログは LogSV として登録する
- どの SV も materialize される
- ワークロードのみに基づいて透過的に SV を作成する
Storage View Example
- ある SV から 別の SV を作成する
- こうして形成される SV のグラフを SV Lattice と呼ぶ
- (このセクションの Example を表すと以下のようになる)
- こうして形成される SV のグラフを SV Lattice と呼ぶ
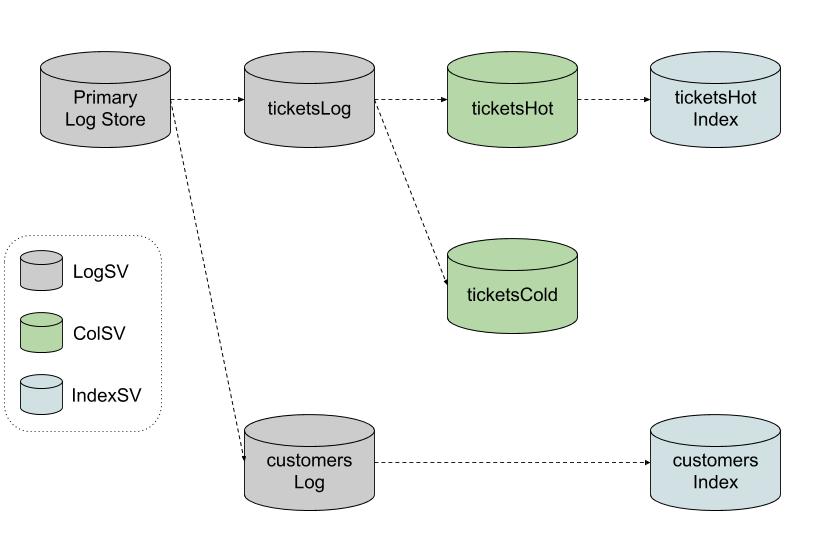
Holistic SV Optimizer
- クエリを実行する際にどの SV を参照するか、どのようにレコードの update を伝播させていくかを決める
- それぞれのコストを見て決める
- クエリのコスト
- update のコスト
- SV 変換のコスト
- Optimizer の機能は以下のようなものになる
- SV Rearrangement: query cost や update cost のバランスを取って、SV lattice を調整する
- Operator Log-Pushdown: クエリの内容から、操作を各 SV に pushdown する
- Adaptive Partial SVs: クエリのスピードアップの為に、新たな SV を作成する
- Stream Transformation: window で区切った継続的なクエリの実行
- それぞれのコストを見て決める
Purging and Checkpoints
- Primary Log Stora が大きくなってくると、ログのサイズを小さくする必要がある
- Purge / Compression / Checkpoint を設けて SV に退避する
Recovery
- ログは durale storage に保存しているので、SV を再作成すれば良い
- Checkpoint でログを退避している場合には、そこからログを復旧させる
Transaction And Isonation
- committed なレコードのみを伝播させる
- uncommitted なトランザクションは committed なレコードしか読めない
Conclusion
OctopusDB は、以下の点が面白いと思いました。
- ストレージを抽象化し、データの更新を伝播させていく
- SV Lattice を使い、クエリの実行やデータの更新を コストベースで最適化していく
次は、複数の抽象化されたストレージの特性を参照しながら最適な実行計画を構築する具体的な手法を探してみたいと思います。