Postgres Advent Calendar 2019 の 15 日目の記事です。
PostgreSQL 12 で、JIT が default で on になりました。そこで JIT まわりのパラメータを変更しながら、生成されるコードや、クエリの応答速度がどう変わるかを確認してみました。
Disassemble Code
JIT でクエリを処理した時に生成されたコードをファイルに出力するには、jit_dump_bitcode を on にします。
set jit_dump_bitcode to on;まずは簡単な SQL を実行して、生成されるコードを眺めてみます。
select l_orderkey, l_partkey, l_suppkey from lineitem where l_tax > 0.07;クエリを投げると、以下の場所に .bc ファイルが生成されます。
ls -l /var/lib/postgresql/12/main/*.bc
-rw------- 1 postgres postgres 11268 Dec 14 08:35 /var/lib/postgresql/12/main/2832.0.bc
-rw------- 1 postgres postgres 7260 Dec 14 08:35 /var/lib/postgresql/12/main/2832.0.optimized.bcこの .bc ファイルを llvm-dis で disassemble して LLVM IR を出力します。ついでに llvm-cbe で C言語のコードとしても出力してみます。(.optimized.bc は読むのがツラそうなので触れません…)
llvm-dis -o 2832.0.ll /var/lib/postgresql/12/main/2832.0.bc
llvm-cbe -o 2832.0.c /var/lib/postgresql/12/main/2832.0.bc出力されたコードは、サイズが大きいので以下にアップしました。
- 2832.0.ll: https://gist.github.com/masayuki038/cee2b28e0d6032de357829063447b922
- 2832.0.c: https://gist.github.com/masayuki038/63940753083bc34e80279036ae1574bd
しかし、出力してみたものの、思った以上に読めなそうです…。取り敢えず、読めそうなところを読んでみます。
Read Code
Filter / Output
生成されたコードを見る前に、コードを出力したクエリの実行計画を見ておきます。
testdb=# explain verbose select l_orderkey, l_partkey, l_suppkey from lineitem where l_tax > 0.07;
QUERY PLAN
-------------------------------------------------------------------------------
Seq Scan on public.lineitem (cost=0.00..1874334.60 rows=6652160 width=12)
Output: l_orderkey, l_partkey, l_suppkey
Filter: (lineitem.l_tax > 0.07)
JIT:
Functions: 4
Options: Inlining true, Optimization true, Expressions true, Deforming true
(6 rows)実行計画から、Seq Scan / Output / Filter の各処理があることがわかります。
コードの構成を軽く眺めてみます。生成されたコードは、Struct の定義 + 2つの関数(evalexpr_0_0, evalexpr_0_2) という 3 つのパートで構成されています。それぞれの関数は、deform_0_0, deform_0_2 という関数を呼び出しています。この deform というのは、ディスク上のタプルをメモリ上の表現に変換する処理です。
evalexpr_0_2 には、numeric_gt という関数を呼び出している箇所があります。
llvm_cbe_b_2e_2_2e_no_2d_null_2d_args:
(... snip ...)
llvm_cbe_funccall = numeric_gt(((struct l_struct_struct_OC_FunctionCallInfoBaseData*
(... snip ...)
goto llvm_cbe_b_2e_op_2e_3_2e_start;ここから evalexpr_0_2 は Filter の時に生成される関数であると考えられます。試しに where 句を除いた SQL を実行して IR を見てみます。
select l_orderkey, l_partkey, l_suppkey from lineitem;すると、やはり evalexpr_0_2 は出力されませんでした。このことから、evalexpr_0_2 は Filter で、evalexpr_0_0 は Output にあたる処理と考えられます。
evalexpr_0_0 から呼び出される deform_0_1 の以下のブロックが、最終的に出力される l_orderkey , l_partkey , l_suppkey という 3 つのフィールドを読み出しているのではないかと思います。
llvm_cbe_find_startblock:
llvm_cbe_tmp__18 = *llvm_cbe_tmp__15;
switch (llvm_cbe_tmp__18) {
default:
goto llvm_cbe_deadblock;
case ((uint16_t)0):
goto llvm_cbe_block_2e_attr_2e_0_2e_attcheckattno;
case ((uint16_t)1):
goto llvm_cbe_block_2e_attr_2e_1_2e_attcheckattno;
case ((uint16_t)2):
goto llvm_cbe_block_2e_attr_2e_2_2e_attcheckattno;
}Deforming on / off
jit_tuple_deforming が on の時には、op.0.fetch で以下のような IR が生成されます。
op.0.fetch: ; preds = %b.op.0.start
call void @deform_0_1(%struct.TupleTableSlot* %v_scanslot)
br label %b.op.1.startそして @deform_0_1 関数も生成されます。
; Function Attrs: norecurse nounwind uwtable
define internal void @deform_0_1(%struct.TupleTableSlot* align 8) #0 {
... (snip) ...しかし、また、jit_tuple_deforming を off にすると、それぞれの関数 ( evalexpr_0_0 , evalexpr_0_2 )に対応する deform 関数は生成されなくなります。
op.0.fetch は以下のように変わります。
op.0.fetch: ; preds = %b.op.0.start
call void bitcast (void (%struct.TupleTableSlot.9302*, i32)* @slot_getsomeattrs_int to void (%struct.TupleTableSlot*, i32)*)(%struct.TupleTableSlot* %v_scanslot, i32 8)
br label %b.op.1.startPerformance
手元の環境(vCPU x 4、メモリ 15 GB) で、JIT のオプションを変えながら、PC-H Q01 の SQL を 5回ずつ計測してみました。
- non-jit: JIT を無効
- jit (all on): デフォルト
- jit deforming off: deforming を off
- jit inline off: jit_inline_above_cost の値を上げて、インライン化を避ける
- jit optimize off: jit_optimize_above_cost の値を上げて、最適化を避ける
TPC-H 測定用のデータを DBGEN で生成しています。
./dbgen -s 10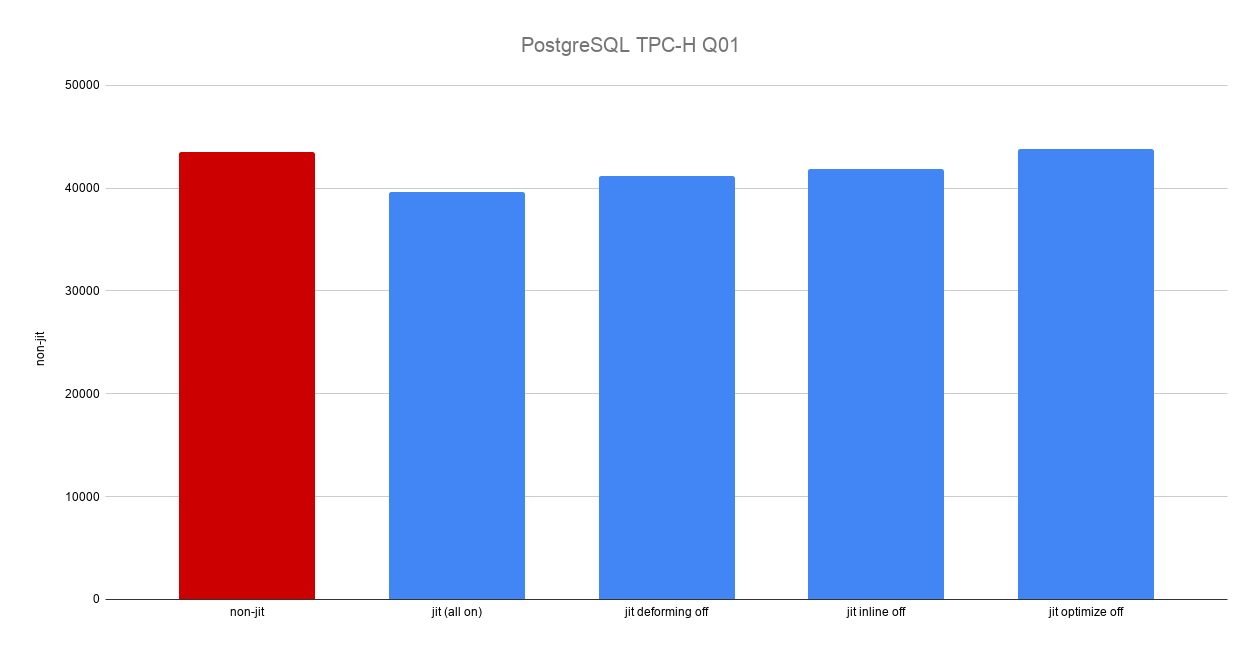
今回の環境では、non-jit に対して jit が 10% 程度速い結果となりました。また、deforming / inline / optimization の何れを off にしても遅くなりました。
Conclusion
今回は PostgreSQL の JIT で生成されるコードを眺めてみました。LLVM IR と C 言語で出力してみましたが、思った以上に読みにくいコードが生成されていたので、これらの理解にはもうちょっと知識と技を身に付ける必要がありますね…。それでも LLVM を知る良い機会となりました。