couch_db_updater:init_db/6の以下の部分を掘り下げてみたいと思います。
couch_db_updater.erl:
1 {ok, IdBtree} = couch_btree:open(Header#db_header.fulldocinfo_by_id_btree_state, Fd,
2 [{split, fun(X) -> btree_by_id_split(X) end},
3 {join, fun(X,Y) -> btree_by_id_join(X,Y) end},
4 {reduce, fun(X,Y) -> btree_by_id_reduce(X,Y) end},
5 {compression, Compression}]),
6 {ok, SeqBtree} = couch_btree:open(Header#db_header.docinfo_by_seq_btree_state, Fd,
7 [{split, fun(X) -> btree_by_seq_split(X) end},
8 {join, fun(X,Y) -> btree_by_seq_join(X,Y) end},
9 {reduce, fun(X,Y) -> btree_by_seq_reduce(X,Y) end},
10 {compression, Compression}]),
11 {ok, LocalDocsBtree} = couch_btree:open(Header#db_header.local_docs_btree_state, Fd,
12 [{compression, Compression}]),couch_db_updater:btree_by_id_split/1
IdBtree、SeqBtree、LocalDocsBtreeの3つのtreeの用意が行われています。まずはIdBtreeの初期化の部分。splitには以下の関数が設定されています。
couch_db_updater.erl:
1btree_by_id_split(#full_doc_info{id=Id, update_seq=Seq,
2 deleted=Deleted, rev_tree=Tree}) ->
3(...snip...)full_doc_infoというドキュメントを扱っています。レコードの定義は以下のようになっています。
couch_db.hrl:
1record(full_doc_info,
2 {id = <<"">>,
3 update_seq = 0,
4 deleted = false,
5 rev_tree = [],
6 leafs_size = 0
7 }).idはドキュメントのID、update_seqは文字通り更新毎にインクリメントされていくシーケンスですかね。rev_treeはこのドキュメントの履歴を管理するリストかな。couch_key_tree:map/2を見てみます。
couch_key_tree.erl:
1map(_Fun, []) ->
2 [];
3map(Fun, [{Pos, Tree}|Rest]) ->
4 case erlang:fun_info(Fun, arity) of
5 {arity, 2} ->
6 [NewTree] = map_simple(fun(A,B,_C) -> Fun(A,B) end, Pos, [Tree]),
7 [{Pos, NewTree} | map(Fun, Rest)];
8 {arity, 3} ->
9 [NewTree] = map_simple(Fun, Pos, [Tree]),
10 [{Pos, NewTree} | map(Fun, Rest)]
11 end.erlang:fun_info/2で関数のメタ情報が取れるようです。couch_key_tree:map_simple/3の第一引数のFunのarityの数を見て呼び出し方を調整しています。couch_db_updater:btree_by_id_split/1の中でこの関数を呼び出す際に渡している無名関数の引数の数は2なので、{arity, 2}の方にマッチすることになります。そうなると、couch_key_tree:simple_map/3の第一引数Funの_Cは何か気になります。
couch_key_tree.erl:
1map_simple(_Fun, _Pos, []) ->
2 [];
3map_simple(Fun, Pos, [{Key, Value, SubTree} | RestTree]) ->
4 Value2 = Fun({Pos, Key}, Value,
5 if SubTree == [] -> leaf; true -> branch end),
6 [{Key, Value2, map_simple(Fun, Pos + 1, SubTree)} | map_simple(Fun, Pos, RestTree)]._Cの部分は
if SubTree == [] -> leaf; true -> branch endなので、_Cにはleafもしくはbranchが指定されることになり、couch_db_updater:btree_by_id_split/1からの呼び出しシーケンスではこの値は参照しなくても処理できる、というなのでしょう。
ちょっと戻り値が分かりにくくなったので整理すると、引数と戻り値の関係は以下のようになっています。
couch_key_tree:map/2
Fun, [{Pos, Tree}, ...] => [{Pos, NewTree}, ...]couch_key_tree:map_simple/2
Fun, Pos, [{Key, Value, SubTree}, ...] => [{Key, Value2, [{SubKey, SubValue2, [...]}]}, ...]ここでcouch_db_updater:btree_by_id_split/1戻ります。
couch_db_updater.erl:
1btree_by_id_split(#full_doc_info{id=Id, update_seq=Seq,
2 deleted=Deleted, rev_tree=Tree}) ->
3 DiskTree =
4 couch_key_tree:map(
5 fun(_RevId, ?REV_MISSING) ->
6 ?REV_MISSING;
7 (_RevId, RevValue) ->
8 IsDeleted = element(1, RevValue),
9 BodyPointer = element(2, RevValue),
10 UpdateSeq = element(3, RevValue),
11 Size = case tuple_size(RevValue) of
12 4 ->
13 element(4, RevValue);
14 3 ->
15 % pre 1.2 format, will be upgraded on compaction
16 nil
17 end,
18 {if IsDeleted -> 1; true -> 0 end, BodyPointer, UpdateSeq, Size}
19 end, Tree),
20 {Id, {Seq, if Deleted -> 1; true -> 0 end, DiskTree}}.rev_treeに保存された{Key, Value}が(_RevId, RevValue)に対応することになります。_RevIdは無視されます。
RevValueは{IsDeleted, BodyPointer, UpdateSeq, Size}で、{Deleted, BodyPointer, UpdateSeq, Size}に変換されます。この変換を図にすると、以下のようになります。
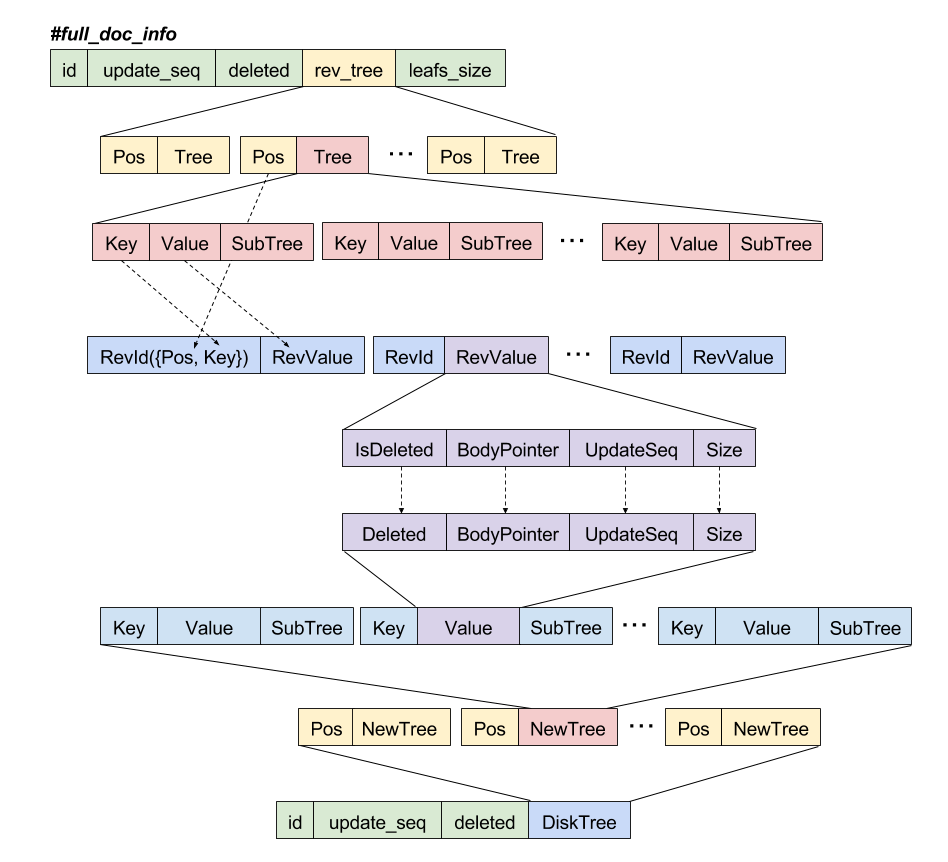
シンボルと変数名がごちゃ混ぜですが、単なる備忘録なのでご容赦を。leaf_sizeが無くなっており、Deletedがtrue/falseから1/0に変わっているところが違いになります。現時点ではこの変換が何を意味するのか分かってませんが、splitに設定された関数を呼び出すと、#full_doc_infoが上記図の一番下部のタプルに変換されることになります。
couch_db_updater:btree_by_id_join/2
次にjoinに設定されているbtree_by_id_join/2ですが、これはパッと見でbtree_by_id_split/1の逆を行うことが分かるので細かく読まないことにしますが、#full_doc_info.leaf_sizeはこの契機で計算しなおしてます。
couch_db_updater.erl:
1btree_by_id_join(Id, {HighSeq, Deleted, DiskTree}) ->
2 {Tree, LeafsSize} =
3 couch_key_tree:mapfold(
4 fun(_RevId, {IsDeleted, BodyPointer, UpdateSeq}, leaf, _Acc) ->
5 % pre 1.2 format, will be upgraded on compaction
6 {{IsDeleted == 1, BodyPointer, UpdateSeq, nil}, nil};
7 (_RevId, {IsDeleted, BodyPointer, UpdateSeq}, branch, Acc) ->
8 {{IsDeleted == 1, BodyPointer, UpdateSeq, nil}, Acc};
9 (_RevId, {IsDeleted, BodyPointer, UpdateSeq, Size}, leaf, Acc) ->
10 Acc2 = sum_leaf_sizes(Acc, Size),
11 {{IsDeleted == 1, BodyPointer, UpdateSeq, Size}, Acc2};
12 (_RevId, {IsDeleted, BodyPointer, UpdateSeq, Size}, branch, Acc) ->
13 {{IsDeleted == 1, BodyPointer, UpdateSeq, Size}, Acc};
14 (_RevId, ?REV_MISSING, _Type, Acc) ->
15 {?REV_MISSING, Acc}
16 end, 0, DiskTree),
17 #full_doc_info{
18 id = Id,
19 update_seq = HighSeq,
20 deleted = (Deleted == 1),
21 rev_tree = Tree,
22 leafs_size = LeafsSize
23 }.couch_db_updater:btree_by_id_reduce/2
そしてreduceに設定されているbtree_by_id_redulce/2ですが、これは第一引数がreduceかrereduceかで処理が分かれています。まずはreduceから。
couch_db_updater.erl:
1btree_by_id_reduce(reduce, FullDocInfos) ->
2 lists:foldl(
3 fun(Info, {NotDeleted, Deleted, Size}) ->
4 Size2 = sum_leaf_sizes(Size, Info#full_doc_info.leafs_size),
5 case Info#full_doc_info.deleted of
6 true ->
7 {NotDeleted, Deleted + 1, Size2};
8 false ->
9 {NotDeleted + 1, Deleted, Size2}
10 end
11 end,
12 {0, 0, 0}, FullDocInfos);引数に指定された#full_doc_infoのリストをまわし、削除済みドキュメントの数、未削除のドキュメントの数、#full_doc_info.leafs_sizeの総数を算出して返します。#full_doc_info.leafs_sizeの総数を求める際、couch_db_updater:sum_leaf_size/2を呼び出しているのが気になったのでコードを見てみました。
couch_db_updater.erl:
1sum_leaf_sizes(nil, _) ->
2 nil;
3sum_leaf_sizes(_, nil) ->
4 nil;
5sum_leaf_sizes(Size1, Size2) ->
6 Size1 + Size2.思ったよりも普通でした。次にrereduceを指定している方を読んでみます。
couch_db_updater.erl:
1btree_by_id_reduce(rereduce, Reds) ->
2 lists:foldl(
3 fun({NotDeleted, Deleted}, {AccNotDeleted, AccDeleted, _AccSize}) ->
4 % pre 1.2 format, will be upgraded on compaction
5 {AccNotDeleted + NotDeleted, AccDeleted + Deleted, nil};
6 ({NotDeleted, Deleted, Size}, {AccNotDeleted, AccDeleted, AccSize}) ->
7 AccSize2 = sum_leaf_sizes(AccSize, Size),
8 {AccNotDeleted + NotDeleted, AccDeleted + Deleted, AccSize2}
9 end,
10 {0, 0, 0}, Reds).reduceと異なるのは、第二引数で指定されているのが#full_doc_infoのリストではなく、{NotDeleted, Deleted}か{NotDeleted, Deleted, Size}のリストであること。処理内容はreduceと同じです。
couch_db_updater:btree_by_seq_split/1
次にSeqBtreeの方を。現時点でIdBtreeとの役割の違いが分かっていないので、推測できる部分が少ないのがツラいところです。
couch_db_updater.erl:
1btree_by_seq_split(#doc_info{id=Id, high_seq=KeySeq, revs=Revs}) ->
2 {RevInfos, DeletedRevInfos} = lists:foldl(
3 fun(#rev_info{deleted = false, seq = Seq} = Ri, {Acc, AccDel}) ->
4 {[{Ri#rev_info.rev, Seq, Ri#rev_info.body_sp} | Acc], AccDel};
5 (#rev_info{deleted = true, seq = Seq} = Ri, {Acc, AccDel}) ->
6 {Acc, [{Ri#rev_info.rev, Seq, Ri#rev_info.body_sp} | AccDel]}
7 end,
8 {[], []}, Revs),
9 {KeySeq, {Id, lists:reverse(RevInfos), lists:reverse(DeletedRevInfos)}}.今度は#doc_infoというレコードを使っています。レコードの定義は以下のとおりです。
couch_db.hrl:
1-record(doc_info,
2 {
3 id = <<"">>,
4 high_seq = 0,
5 revs = [] % rev_info
6 }).#full_doc_infoと照らし合わせて推測すると、idは#full_doc_info.idと同じで、high_seqは#full_doc_info.update_seqの最も高い値、revsは#full_doc_info.rev_treeに対応しているように見えます。また、revsには#ref_infoレコードのリストが設定されるようになっているので、このレコードの定義も確認します。
couch_db.hrl:
1-record(rev_info,
2 {
3 rev,
4 seq = 0,
5 deleted = false,
6 body_sp = nil % stream pointer
7 }).個々のリビジョンの情報なのかな。body_spが#full_doc_info.rev_treeのValueにあったBodyPointerと違うものなのかが気になります。
btree_by_seq_split/1に戻ると、#doc_info.revsをまわして、未削除の#rev_infoと削除済みの#rev_infoに分けています。最終的に{high_seq, {id, RevInfos, DeletedRevInfos}}として返します。
couch_db_updater:btree_by_seq_join/2
次にjoinに設定されているbtree_by_seq_join/2ですが、やはりbtree_by_seq_split/1の逆の処理を行う関数なのでパっと見るだけで。
couch_db_updater.erl:
1btree_by_seq_join(KeySeq, {Id, RevInfos, DeletedRevInfos}) ->
2 #doc_info{
3 id = Id,
4 high_seq=KeySeq,
5 revs =
6 [#rev_info{rev=Rev,seq=Seq,deleted=false,body_sp = Bp} ||
7 {Rev, Seq, Bp} <- RevInfos] ++
8 [#rev_info{rev=Rev,seq=Seq,deleted=true,body_sp = Bp} ||
9 {Rev, Seq, Bp} <- DeletedRevInfos]}.couch_db_updater:btree_by_seq_reduce/2
そしてreduceに設定されているbtree_by_seq_reduce/2。reduceが指定された場合は#doc_infoのリストの要素数を返しているだけ。rereduceはlists:sum/1を呼び出しているので、Redsは
[number()]かな。
couch_db_updater.erl:
1btree_by_seq_reduce(reduce, DocInfos) ->
2 % count the number of documents
3 length(DocInfos);
4btree_by_seq_reduce(rereduce, Reds) ->
5 lists:sum(Reds).couch_btree:open/3
IdBtree、SeqBtreeと読んできたのでLocalDocsBtreeの番ですが、これはsplitやjoin、reduceといった関数が設定されていないので、couch_btree:open/3を読んでみようと思います。
couch_btree.erl:
1open(State, Fd, Options) ->
2 {ok, set_options(#btree{root=State, fd=Fd}, Options)}.StateはIdBtree、SeqBtree、LocalDocsBtree毎に異なる値が設定されています。set_options/2も見てみます。
couch_btree.erl:
1set_options(Bt, []) ->
2 Bt;
3set_options(Bt, [{split, Extract}|Rest]) ->
4 set_options(Bt#btree{extract_kv=Extract}, Rest);
5set_options(Bt, [{join, Assemble}|Rest]) ->
6 set_options(Bt#btree{assemble_kv=Assemble}, Rest);
7set_options(Bt, [{less, Less}|Rest]) ->
8 set_options(Bt#btree{less=Less}, Rest);
9set_options(Bt, [{reduce, Reduce}|Rest]) ->
10 set_options(Bt#btree{reduce=Reduce}, Rest);
11set_options(Bt, [{compression, Comp}|Rest]) ->
12 set_options(Bt#btree{compression=Comp}, Rest).split、join、reduceに設定された各関数がそれぞれ、extract_kv、assemble_kv、reduceという名前で#btreeに設定されています。compressionも同様です。lessはまだ出てきてませんが、どういう役割なのか気になります。
Conclusion
各Btreeの初期化処理を見てきました。ここまで見てきた限りでは、IdBtreeはドキュメントそのもの、SeqBtreeは各ドキュメントの最新Seqの管理を行っているように見受けられます。LocalDocsBtreeはまだ分かりません。このBtreeに関してはもう少し読み進めていく中で役割を確認しようと思います。