NIO ByteBuffer
前回の続き。結局、BSONEncoder#_putのUTF-8変換のコードが遅い理由が分からなかったので、UTF-8のバイト配列を生成する為に使用しているByteArrayOutputStreamをNIOのByteBufferに変えてみました。
1 static byte[] getUtf8(String str) {
2 ByteBuffer _buf = null;
3 _buf = ByteBuffer.allocate(str.length() * 5);
4
5 final int len = str.length();
6 int total = 0;
7
8 for (int i = 0; i < len;) {
9 int c = Character.codePointAt(str, i);
10
11 if (c < 0x80) {
12 _buf.put((byte) c);
13 total += 1;
14 } else if (c < 0x800) {
15 _buf.put((byte) (0xc0 + (c >> 6)));
16 _buf.put((byte) (0x80 + (c & 0x3f)));
17 total += 2;
18 } else if (c < 0x10000) {
19 _buf.put((byte) (0xe0 + (c >> 12)));
20 _buf.put((byte) (0x80 + ((c >> 6) & 0x3f)));
21 _buf.put((byte) (0x80 + (c & 0x3f)));
22 total += 3;
23 } else {
24 _buf.put((byte) (0xf0 + (c >> 18)));
25 _buf.put((byte) (0x80 + ((c >> 12) & 0x3f)));
26 _buf.put((byte) (0x80 + ((c >> 6) & 0x3f)));
27 _buf.put((byte) (0x80 + (c & 0x3f)));
28 total += 4;
29 }
30
31 i += Character.charCount(c);
32 }
33
34 _buf.flip();
35 byte[] ret = new byte[_buf.limit()];
36 _buf.get(ret);
37 return ret;
38 }ByteArrayOutputStreamをByteBufferに変えて計測してみたところ、大分速くなりました。文字列長100でByteArrayOutputStreamの約1.8倍、1000だと約1.6倍になりました。また、10文字であればString#getBytes(“UTF-8”)よりもちょっとだけ速くなりました。
byte[]
ByteBufferの結果から、UTF-8に変換したバイト配列をバッファに格納する箇所が遅いことが分かったので、今度はByteBufferではなくbyte[]に直接格納するようにしてみました。
1 static byte[] getUtf8(String str) {
2 byte[] _buf = new byte[str.length() * 5];
3
4 final int len = str.length();
5 int total = 0;
6
7 int idx = 0;
8 for (int i = 0; i < len;) {
9 int c = Character.codePointAt(str, i);
10
11 if (c < 0x80) {
12 _buf[idx++] = (byte) c;
13 total += 1;
14 } else if (c < 0x800) {
15 _buf[idx++] = (byte) (0xc0 + (c >> 6));
16 _buf[idx++] = (byte) (0x80 + (c & 0x3f));
17 total += 2;
18 } else if (c < 0x10000) {
19 _buf[idx++] = (byte) (0xe0 + (c >> 12));
20 _buf[idx++] = (byte) (0x80 + ((c >> 6) & 0x3f));
21 _buf[idx++] = (byte) (0x80 + (c & 0x3f));
22 total += 3;
23 } else {
24 _buf[idx++] = (byte) (0xf0 + (c >> 18));
25 _buf[idx++] = (byte) (0x80 + ((c >> 12) & 0x3f));
26 _buf[idx++] = (byte) (0x80 + ((c >> 6) & 0x3f));
27 _buf[idx++] = (byte) (0x80 + (c & 0x3f));
28 total += 4;
29 }
30
31 i += Character.charCount(c);
32 }
33
34 byte[] ret = new byte[idx];
35 System.arraycopy(_buf, 0, ret, 0, ret.length);
36 return ret;
37 }文字列長が10文字の場合はString#getBytes(“UTF-8”)の約1.5倍の速さで処理できます。しかし、やはり文字列長が増えるとString#getBytes(“UTF-8”)の方が速い結果となっています。ByteBuffer、byte[]を加えた処理時間の推移は以下となります。
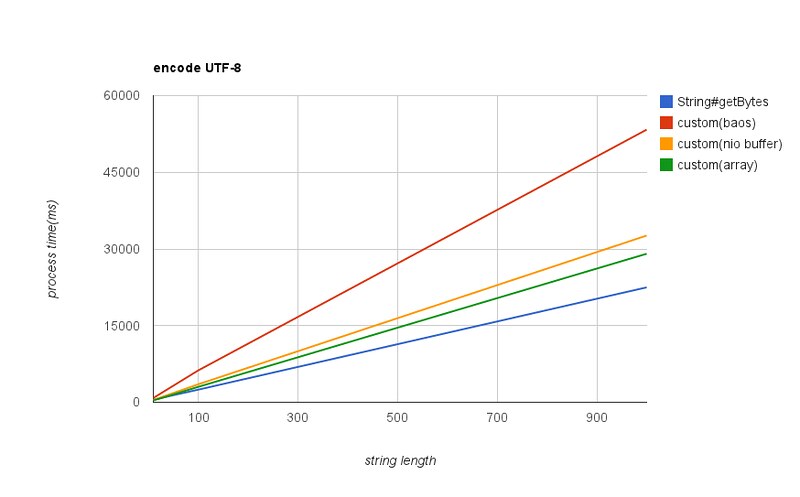
結局、文字列が長くなるとString#getBytes(“UTF-8”)が一番速くなっています。うーん。
hprof=cpu=samples
前回のプロファイリングの結果では、UTF-8変換後のバイト配列をバッファに保存する部分はtop10に入っていませんでした。しかし、バッファに保存する部分を変更した結果、パフォーマンスがかなり向上しました。つまり、hprof=cpu=samplesのプロファイリングの仕方では、ボトルネックの検出は難しいということになります。
hprof=cpu=samplesを指定すると、サンプリング用のスレッドが定期的に各スレッドのスタックトレースを取得します。前回は以下の設定でプロファイリングを行いました。
-agentlib:hprof=cpu=samples,file=result.hprof,depth=20samplingの間隔はデフォルトで10msとなっています。この間隔を1msにし、コードをByteArrayOutputStreamを使用する形に戻して、再度プロファイリングしてみました。
-agentlib:hprof=cpu=samples,interval=1,file=result.hprof,depth=20結果は以下となっています。
CPU SAMPLES BEGIN (total = 7001) Sun May 6 18:30:33 2012
rank self accum count trace method
1 15.30% 15.30% 1071 300077 net.wrap_trap.example.encode.EncodeUTF8Test.getUtf8
2 14.96% 30.25% 1047 300071 net.wrap_trap.example.encode.EncodeUTF8Test.getUtf8
3 14.27% 44.52% 999 300075 net.wrap_trap.example.encode.EncodeUTF8Test.getUtf8
4 12.70% 57.22% 889 300072 net.wrap_trap.example.encode.EncodeUTF8Test.getUtf8
5 11.97% 69.19% 838 300081 java.lang.Character.codePointAt
6 11.04% 80.23% 773 300079 java.io.ByteArrayOutputStream.<init>
7 6.61% 86.84% 463 300080 net.wrap_trap.example.encode.EncodeUTF8Test.getUtf8
8 2.91% 89.76% 204 300076 net.wrap_trap.example.encode.EncodeUTF8Test.getUtf8
9 2.70% 92.46% 189 300078 net.wrap_trap.example.encode.EncodeUTF8Test$2.getUtf8Bytes
10 1.54% 94.00% 108 300073 java.lang.String.lengthrank6にByteArrayOutputStream#
hprof=cpu=times
CPU使用率のプロファイリングの仕方として、hprof=cpu=samplesの他に、hprof=cpu=timesがあります。これはサンプリング方式と異なり、全てのメソッドの実行時間を取得することができます。ただし、計測用のバイトコードを実行コードに入れる形で行われる為、実行時間がかなり延びます。
hprof=cpu=timesでプロファイリングしてみました。実行回数は、これまでのように1,000,000回とすると1時間以上経っても終わらなかったので1000回とし、文字列長は1000としました。
-agentlib:hprof=times,file=result.hprof,depth=20top 10は以下となります。
CPU TIME (ms) BEGIN (total = 85813) Sun May 6 23:24:28 2012
rank self accum count trace method
1 31.57% 31.57% 2 302880 java.lang.Object.wait
2 25.98% 57.55% 11000 302513 net.wrap_trap.example.encode.EncodeUTF8Test.getUtf8
3 15.54% 73.09% 1103000 302506 java.lang.Character.codePointAt
4 11.91% 85.00% 3049000 302507 java.io.ByteArrayOutputStream.write
5 4.45% 89.45% 1130000 302504 java.lang.String.charAt
6 4.30% 93.76% 1103000 302505 java.lang.Character.isHighSurrogate
7 4.27% 98.03% 1103000 302508 java.lang.Character.charCount
8 0.18% 98.21% 10000 302461 java.lang.Long.toString
9 0.13% 98.34% 1 303602 net.wrap_trap.example.encode.EncodeUTF8Test.main
10 0.12% 98.46% 11000 302510 java.util.Arrays.copyOfrank1はjava.lang.ref.Reference$ReferenceHandlerなのでスルーします。rank2はhprof=cpu=samplesと同様に直接UTF-8のバイト配列に変換しているメソッドでした。rank3もsamplesでtop 10に入ってましたが、それ以降はsamplesの結果と異なっています。
rank4のByteArrayOutputStream#writeですが、この部分を別の実装にすることで大分速くなったので、このメソッドが上位に来ることは納得できます。
top7までの呼び出しシーケンスは以下のとおりです。
TRACE 302880: (thread=200003)
java.lang.Object.wait(Object.java:Unknown line)
java.lang.ref.Reference$ReferenceHandler.run(Reference.java:Unknown line)
TRACE 302513: (thread=200001)
net.wrap_trap.example.encode.EncodeUTF8Test.getUtf8(EncodeUTF8Test.java:Unknown line)
net.wrap_trap.example.encode.EncodeUTF8Test$2.getUtf8Bytes(EncodeUTF8Test.java:Unknown line)
net.wrap_trap.example.encode.EncodeUTF8Test.main(EncodeUTF8Test.java:Unknown line)
TRACE 302506: (thread=200001)
java.lang.Character.codePointAt(Character.java:Unknown line)
net.wrap_trap.example.encode.EncodeUTF8Test.getUtf8(EncodeUTF8Test.java:Unknown line)
net.wrap_trap.example.encode.EncodeUTF8Test$2.getUtf8Bytes(EncodeUTF8Test.java:Unknown line)
net.wrap_trap.example.encode.EncodeUTF8Test.main(EncodeUTF8Test.java:Unknown line)
TRACE 302507: (thread=200001)
java.io.ByteArrayOutputStream.write(ByteArrayOutputStream.java:Unknown line)
net.wrap_trap.example.encode.EncodeUTF8Test.getUtf8(EncodeUTF8Test.java:Unknown line)
net.wrap_trap.example.encode.EncodeUTF8Test$2.getUtf8Bytes(EncodeUTF8Test.java:Unknown line)
net.wrap_trap.example.encode.EncodeUTF8Test.main(EncodeUTF8Test.java:Unknown line)
TRACE 302504: (thread=200001)
java.lang.String.charAt(String.java:Unknown line)
java.lang.Character.codePointAt(Character.java:Unknown line)
net.wrap_trap.example.encode.EncodeUTF8Test.getUtf8(EncodeUTF8Test.java:Unknown line)
net.wrap_trap.example.encode.EncodeUTF8Test$2.getUtf8Bytes(EncodeUTF8Test.java:Unknown line)
net.wrap_trap.example.encode.EncodeUTF8Test.main(EncodeUTF8Test.java:Unknown line)
TRACE 302505: (thread=200001)
java.lang.Character.isHighSurrogate(Character.java:Unknown line)
java.lang.Character.codePointAt(Character.java:Unknown line)
net.wrap_trap.example.encode.EncodeUTF8Test.getUtf8(EncodeUTF8Test.java:Unknown line)
net.wrap_trap.example.encode.EncodeUTF8Test$2.getUtf8Bytes(EncodeUTF8Test.java:Unknown line)
net.wrap_trap.example.encode.EncodeUTF8Test.main(EncodeUTF8Test.java:Unknown line)
TRACE 302508: (thread=200001)
java.lang.Character.charCount(Character.java:Unknown line)
net.wrap_trap.example.encode.EncodeUTF8Test.getUtf8(EncodeUTF8Test.java:Unknown line)
net.wrap_trap.example.encode.EncodeUTF8Test$2.getUtf8Bytes(EncodeUTF8Test.java:Unknown line)
net.wrap_trap.example.encode.EncodeUTF8Test.main(EncodeUTF8Test.java:Unknown line)UTF-8に変換しているgetUtf8とByteArrayOutputStream#writeを除くと、Character#codePointAt、Character#charAtの2点が残ります。
TRACE 302504より、Character#codePointAtは内部でCharater#charAtを呼び出しているので、charAtに置き換えたら速くなるのでは、と思ったところで、ようやくCharacter#codePointAtというメソッドの意味が分かりました。このメソッドは単に各Unicode文字のコードを返すのではなく、補助文字のU+10000からU+10FFFFを返せるメソッドになっており、UTF-8に変換する際にこの値を見ることによって補助文字の対応を入れることができている(=サロゲート対応が入っている)ことになります。ですので、codePointAtをcharAtに置き換えることはできません。
sun.nio.cs.UTF8#encodeArrayLoopではこの部分をSurrogate.Parserを使って判定し、変換元文字列はchar[]で扱っている為、Character#codePointAtを呼び出さず、コードの参照も速い(char[]なので)分スピードが出るのかな。
ちなみにCharacter#charCountは補助文字の場合に2が、それ以外は1が返るだけなので、インライン展開すればもしかすると違ってくるかも。でもJITコンパイラがそこまでやってそうな気もします。一応PrintCompilationオプションを使ってgetUtf8がJITコンパイルされていることは確認しました。
Conclusion
- nioのByteBuffer速い
- byte[]だとなお速い
- ByteBufferはByteArrayOutputStreamと違って初期サイズを変更できないので、その点で配列と同じ。速度を気にするなら配列を使う方が良い
- byte[]だとなお速い
- hprof=cpu=samplesの結果は評価が難しい
- とはいえ大きいアプリケーションではtimesを使って計測するのは大変
- samplesで絞り込んで、timesで詳細を確認するとか
- とはいえ大きいアプリケーションではtimesを使って計測するのは大変
- mongo-java-driverのUTF-8変換はサロゲート対応ができている