Which is faster?
前回のプロファイリングにて、文字列をUTF-8に変換する処理に速度差がありそうだという結果になった為、String#getBytes(“UTF-8”)とmongo-java-driverのBSONEncoding#_putのコードの処理時間を比較してみました。
Code
以下のコードで比較しました。
EncodeUTF8Test.java:
1package net.wrap_trap.example.encode;
2
3import java.io.ByteArrayOutputStream;
4import java.io.IOException;
5import java.io.UnsupportedEncodingException;
6
7import org.apache.commons.lang3.RandomStringUtils;
8
9public class EncodeUTF8Test {
10
11 public static void main(String[] args) throws UnsupportedEncodingException {
12 Utf8BytesGenerator generator = null;
13 if (args[0].equals("1")) {
14 generator = new Utf8BytesGenerator() {
15 @Override
16 public byte[] getUtf8Bytes(String str) {
17 try {
18 return str.getBytes("UTF-8");
19 } catch (UnsupportedEncodingException e) {
20 throw new RuntimeException(e);
21 }
22 }
23 };
24 } else if (args[0].equals("2")) {
25 generator = new Utf8BytesGenerator() {
26 @Override
27 public byte[] getUtf8Bytes(String str) {
28 return getUtf8(str);
29 }
30 };
31 }
32
33 int loop = Integer.parseInt(args[1]);
34 int strLen = Integer.parseInt(args[2]);
35
36 // warming up
37 {
38 int total = 0;
39 for (int i = 0; i < 10000; i++) {
40 String str = String.valueOf(System.currentTimeMillis());
41 total += generator.getUtf8Bytes(str).length;
42 }
43 System.out.println("total: " + total);
44 }
45
46 String str = RandomStringUtils.random(strLen);
47
48 int total = 0;
49 long start = System.currentTimeMillis();
50 for (int i = 0; i < loop; i++) {
51 total += generator.getUtf8Bytes(str).length;
52 }
53 System.out.println("total: " + total);
54 System.out.println("average: " + (total / loop));
55 System.out.println("time: " + (System.currentTimeMillis() - start) + " ms");
56 }
57
58 static byte[] getUtf8(String str) {
59 ByteArrayOutputStream _buf = null;
60 try {
61 _buf = new ByteArrayOutputStream(str.length() * 5);
62
63 final int len = str.length();
64 int total = 0;
65
66 for (int i = 0; i < len;) {
67 int c = Character.codePointAt(str, i);
68
69 if (c < 0x80) {
70 _buf.write((byte) c);
71 total += 1;
72 } else if (c < 0x800) {
73 _buf.write((byte) (0xc0 + (c >> 6)));
74 _buf.write((byte) (0x80 + (c & 0x3f)));
75 total += 2;
76 } else if (c < 0x10000) {
77 _buf.write((byte) (0xe0 + (c >> 12)));
78 _buf.write((byte) (0x80 + ((c >> 6) & 0x3f)));
79 _buf.write((byte) (0x80 + (c & 0x3f)));
80 total += 3;
81 } else {
82 _buf.write((byte) (0xf0 + (c >> 18)));
83 _buf.write((byte) (0x80 + ((c >> 12) & 0x3f)));
84 _buf.write((byte) (0x80 + ((c >> 6) & 0x3f)));
85 _buf.write((byte) (0x80 + (c & 0x3f)));
86 total += 4;
87 }
88
89 i += Character.charCount(c);
90 }
91
92 return _buf.toByteArray();
93 } finally {
94 if (_buf != null) {
95 try {
96 _buf.close();
97 } catch (IOException ignore) {}
98 }
99 }
100 }
101
102 interface Utf8BytesGenerator {
103 byte[] getUtf8Bytes(String str);
104 }
105}BSONEncoder#_putのオリジナルのコードは、_buf(org.bson.io.OutputBuffer)に書き込み、書き込んだバイト数を返すようになっているのですが、比較するにあたりByteArrayOutputStreamに書き込み、最後にbyte[]を返すように変更しています。ByteArrayOutputStreamの初期サイズは文字列長の5倍としています。
Measuring
UTF-8に変換する文字列の長さを変えながら2つの方式の処理時間を計測し、グラフにしてみました。
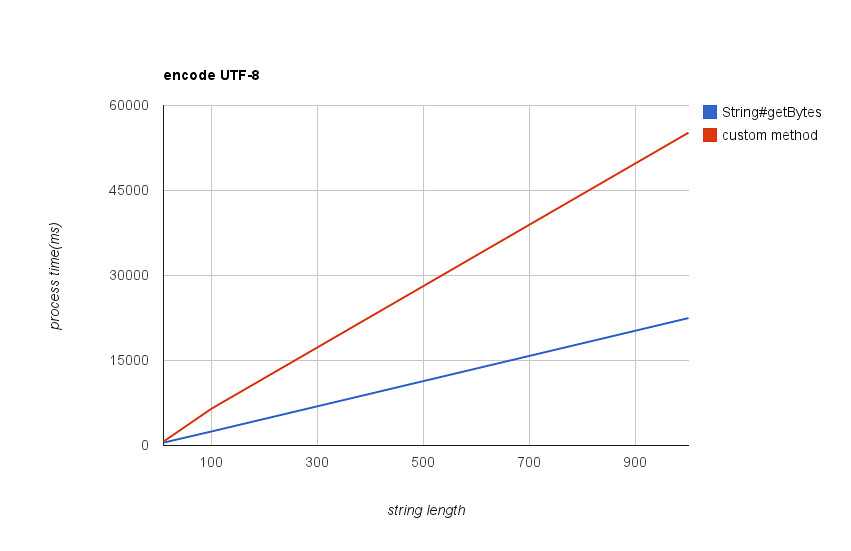
- 実行環境
- Core2Duo(T8100 2.10GHz)
- Ubuntu 8.04(VMWare)
- Java™ SE Runtime Environment (build 1.6.0_24-b07)
全体的にBSONEncoder#_putの方が遅く、String#getBytes(“UTF-8”)と比べると、10文字程度であれば役1.6倍、100文字だと2.5倍程度処理時間がかかる結果となりました。
Profiling
2つのテストケースをhprofを使ってプロファイリングしてみました。プロファイリング時の文字列長は1000です。
BSONEncoder#_put
BSONEncoder#_put(に手を加えたもの)の結果は以下のとおりです(rank 10まで)。
CPU SAMPLES BEGIN (total = 3714) Sat May 5 00:29:53 2012
rank self accum count trace method
1 18.28% 18.28% 679 300063 net.wrap_trap.example.encode.EncodeUTF8Test.getUtf8
2 16.45% 34.73% 611 300061 net.wrap_trap.example.encode.EncodeUTF8Test.getUtf8
3 16.05% 50.78% 596 300060 net.wrap_trap.example.encode.EncodeUTF8Test.getUtf8
4 15.29% 66.07% 568 300067 java.lang.Character.codePointAt
5 14.03% 80.10% 521 300068 net.wrap_trap.example.encode.EncodeUTF8Test.getUtf8
6 7.62% 87.72% 283 300064 net.wrap_trap.example.encode.EncodeUTF8Test.getUtf8
7 3.31% 91.03% 123 300076 net.wrap_trap.example.encode.EncodeUTF8Test.getUtf8
8 2.77% 93.81% 103 300074 net.wrap_trap.example.encode.EncodeUTF8Test$2.getUtf8Bytes
9 1.16% 94.96% 43 300065 java.lang.String.length
10 0.94% 95.91% 35 300066 net.wrap_trap.example.encode.EncodeUTF8Test.getUtf8BSONEncoder#_putの実装を記述したテストクラス(EncodeUTF8Test)がかなり目立っています。ByteArrayOutputStreamのオブジェクトへの操作はtop 10には入ってきていません。
top3のシーケンスを確認してみます。
TRACE 300063:
net.wrap_trap.example.encode.EncodeUTF8Test.getUtf8(EncodeUTF8Test.java:77)
net.wrap_trap.example.encode.EncodeUTF8Test$2.getUtf8Bytes(EncodeUTF8Test.java:28)
net.wrap_trap.example.encode.EncodeUTF8Test.main(EncodeUTF8Test.java:51)
TRACE 300061:
net.wrap_trap.example.encode.EncodeUTF8Test.getUtf8(EncodeUTF8Test.java:79)
net.wrap_trap.example.encode.EncodeUTF8Test$2.getUtf8Bytes(EncodeUTF8Test.java:28)
net.wrap_trap.example.encode.EncodeUTF8Test.main(EncodeUTF8Test.java:51)
TRACE 300060:
net.wrap_trap.example.encode.EncodeUTF8Test.getUtf8(EncodeUTF8Test.java:78)
net.wrap_trap.example.encode.EncodeUTF8Test$2.getUtf8Bytes(EncodeUTF8Test.java:28)
net.wrap_trap.example.encode.EncodeUTF8Test.main(EncodeUTF8Test.java:51)top3がEncodeUTF8Test.javaの77~79行目に集中しており、UTF-8に変換する為のシフト演算をしている部分がヘビーヒットしているようです。String#getBytes(“UTF-8”)の方も確認してみましょう。
String#getBytes(“UTF-8”)
String#getBytes(“UTF-8”)の結果は以下のとおりです。
CPU SAMPLES BEGIN (total = 1636) Fri May 4 22:15:02 2012
rank self accum count trace method
1 46.58% 46.58% 762 300065 sun.nio.cs.UTF_8$Encoder.encodeArrayLoop
2 31.42% 78.00% 514 300061 sun.nio.cs.UTF_8$Encoder.encodeArrayLoop
3 8.99% 86.98% 147 300066 java.lang.StringCoding.encode
4 5.56% 92.54% 91 300069 java.nio.Buffer.<init>
5 2.20% 94.74% 36 300068 sun.nio.cs.Surrogate$Parser.parse
6 1.71% 96.45% 28 300070 java.util.Arrays.copyOf
7 1.22% 97.68% 20 300064 java.lang.StringCoding$StringEncoder.encode
8 1.10% 98.78% 18 300072 sun.nio.cs.UTF_8$Encoder.encodeArrayLoop
9 0.24% 99.02% 4 300054 java.lang.System.currentTimeMillis
10 0.12% 99.14% 2 300073 sun.nio.cs.UTF_8.updatePositions全体の78%を占めるtop2のシーケンスを見てみます。
TRACE 300065:
sun.nio.cs.UTF_8$Encoder.encodeArrayLoop(UTF_8.java:391)
sun.nio.cs.UTF_8$Encoder.encodeLoop(UTF_8.java:447)
java.nio.charset.CharsetEncoder.encode(CharsetEncoder.java:544)
java.lang.StringCoding$StringEncoder.encode(StringCoding.java:240)
java.lang.StringCoding.encode(StringCoding.java:272)
java.lang.String.getBytes(String.java:946)
net.wrap_trap.example.encode.EncodeUTF8Test$1.getUtf8Bytes(EncodeUTF8Test.java:18)
net.wrap_trap.example.encode.EncodeUTF8Test.main(EncodeUTF8Test.java:51)
TRACE 300061:
sun.nio.cs.UTF_8$Encoder.encodeArrayLoop(UTF_8.java:366)
sun.nio.cs.UTF_8$Encoder.encodeLoop(UTF_8.java:447)
java.nio.charset.CharsetEncoder.encode(CharsetEncoder.java:544)
java.lang.StringCoding$StringEncoder.encode(StringCoding.java:240)
java.lang.StringCoding.encode(StringCoding.java:272)
java.lang.String.getBytes(String.java:946)
net.wrap_trap.example.encode.EncodeUTF8Test$1.getUtf8Bytes(EncodeUTF8Test.java:18)
net.wrap_trap.example.encode.EncodeUTF8Test.main(EncodeUTF8Test.java:51)top2ともにUTF-8#encodeArrayLoopの中でした。GrepCodeにOpenJDKの実装が載っていたのでリンクを貼っておきます。BSONEncoder#_putと比較すると、こちらにはサロゲートペアの対応が入っているのが目をひきますが、基本的には1文字ずつ処理しているようです。何が違うんだろう。
GrepCode: sun.nio.cs.UTF8 - Source Code View
他に興味深いのはrank4のシーケンスです。
TRACE 300069:
java.nio.Buffer.<init>(Buffer.java:176)
java.nio.ByteBuffer.<init>(ByteBuffer.java:259)
java.nio.HeapByteBuffer.<init>(HeapByteBuffer.java:52)
java.nio.ByteBuffer.wrap(ByteBuffer.java:350)
java.nio.ByteBuffer.wrap(ByteBuffer.java:373)
java.lang.StringCoding$StringEncoder.encode(StringCoding.java:237)
java.lang.StringCoding.encode(StringCoding.java:272)
java.lang.String.getBytes(String.java:946)
net.wrap_trap.example.encode.EncodeUTF8Test$1.getUtf8Bytes(EncodeUTF8Test.java:18)
net.wrap_trap.example.encode.EncodeUTF8Test.main(EncodeUTF8Test.java:51)byte[]に変換する際に使用しているバッファ領域の確保にjava.nio.ByteBufferが使用されていました。BSONEncoder#_putのコードをbyte[]を返すように書き換えた際、ByteArrayOutputStreamを使うようにしたので、その部分で不利になってしまったかも。
BSONEncoderの_putの中で書き込んでいるバッファのクラスであるorg.bson.io.OutputBuffer、および同パッケージ内のサブクラスに関しては、nioは使用されていませんでした。(確認したコードはmongo-java-driverの2.5.3のものです)
mongo-java-driver / src / main / org / bson / io
また、同パッケージにはPoolOutputBufferというクラスがあり、大きめのバッファを使用したい場合はこちらを使用するようです。このあたりのコードを見るとかなり細かいところまで記述されており、パフォーマンスについて考慮されていることがわかります。
Conclusion
- BSONEncoder#_putによるUTF-8への変換は、変換対象の文字列が長くなると重くなる
- StringからUTF-8のバイト配列を求める場合、String#getBytes(“UTF-8”)は十分速いので自前で書く必要はない
- BSONEncoder#_putのコードが重い原因は分からない
- String#getBytesではnioを使ってバッファを確保している
- BSONEncoder#_putでByteBufferを使ってバッファを確保すれば速くなる可能性はある
- バッファへの書き込みや、バッファからbyte[]を生成する部分は上位に来ていないので、あまり関係ないかも
- String#getBytesではnioを使ってバッファを確保している
Additional Comment
mongo-java-driverにもサロゲート対応が入っているのを確認しました。(2012/05/06)